
「多変量解析入門」という書籍を読んでいると、「線形判別分析による倒産企業の予測」という事例が載っていました。とても面白い事例だなぁと思っていたのですが、そもそも、決算書データを手に入れて解析しやすい形にするにはどうすれば良いのか、というところから始まりました。上場企業であれば決算書データは手に入ります。今回は金融庁が運営しているサイトEDINETからデータを取得したXBRLファイルというファイルを使って行います。
EDINETとは
EDINET(http://info.edinet-fsa.go.jp/)とは、金融庁が行政サービスの一環として運営している有価証券報告書提出会社の有価証券報告書のデータベースです。EDINETでは企業が公開している有報の検索・閲覧・ダウンロードが全て無料で行えます。EDINETとは「Electronic Disclosure for Investors’ NETwork」の略です。
データ取得を行うにもAPIがあるのでとても便利です。APIでのデータ取得方法は次回ご紹介したいと思います。
EDINETからXBRLを取得
XBRLとは、企業の財務諸表や財務報告などを記述するための標準的な形式を定めた規格の一つ。XMLを応用した言語の一つで、一度入力した財務情報を関係機関で共有し、ソフトウェアによる自動処理で伝達、保存、加工などすることができる。
EDINET(http://info.edinet-fsa.go.jp/)より、「書類検索」から取得したい企業を検索すると検索結果にダウンロード可能なファイルが表示されます。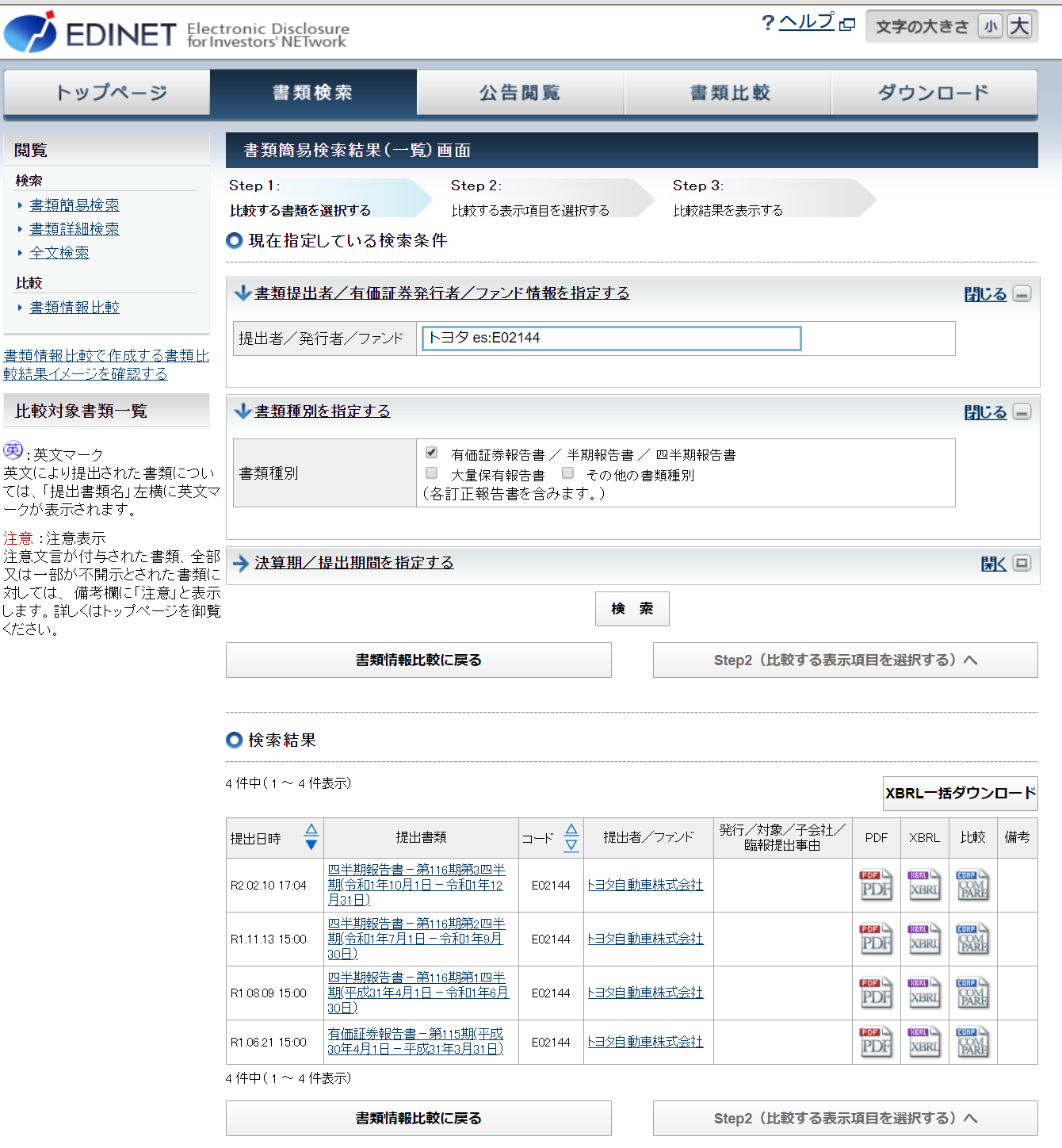
今回は、有価証券報告書のXBRLを使用します。
XBRLファイルのparserにArelle
XBRLはXML形式になっていますが、なかなか欲しいデータをすんなり渡してはくれない複雑仕様です。XBRLをparseするプログラムを作成されているサイトを沢山見ましたが、ゼロから始めないXBRL解析(Arelleの活用)がすごく納得できる内容でしたので、こちらに記載のあるArelleを使用させていただく事にしました。
大問題:要素名が1つに絞れない
XBRLが嫌われている理由の1つが要素名が1つに絞れない事です。例えば「売上高」を取得したいとします。「要素名:NetSales」がそれに該当しますが、企業によっては別の要素名を使用しており、NetSalesでは取得出来ません。IFRS対応企業も別の要素名を使用していたります。まず「売上高」に該当するタグを全て洗い出さないと1つのフォーマットで定義出来ません。
まずは、欲しいデータの要素名を辞書型で定義します。
※ちなみに↓だけでは不足要素名があるかと思います。すみません。。
dict_cols = {
'企業名':
{ 'element_id':['FilerNameInJapaneseDEI']
,'contextRef':'FilingDateInstant'
}
,'EDINETコード':
{ 'element_id':['EDINETCodeDEI']
,'contextRef':'FilingDateInstant'
}
,'提出者業種':
{ 'element_id':[]
,'contextRef':''
}
,'単独/連結':
{ 'element_id':[]
,'contextRef':''
}
,'証券コード':
{ 'element_id':['SecurityCodeDEI']
,'contextRef':'FilingDateInstant'
}
,'当事業年度開始日':
{ 'element_id':['CurrentFiscalYearStartDateDEI']
,'contextRef':'FilingDateInstant'
}
,'当事業年度終了日':
{ 'element_id':['CurrentFiscalYearEndDateDEI']
,'contextRef':'FilingDateInstant'
}
,'平均年間給与(円)':
{ 'element_id':['AverageAnnualSalaryInformationAboutReportingCompanyInformationAboutEmployees']
,'contextRef':'CurrentYearInstant'
}
,'平均勤続年数(年)':
{ 'element_id':['AverageLengthOfServiceYearsInformationAboutReportingCompanyInformationAboutEmployees']
,'contextRef':'CurrentYearInstant'
}
,'平均年齢(歳)':
{ 'element_id':['AverageAgeYearsInformationAboutReportingCompanyInformationAboutEmployees']
,'contextRef':'CurrentYearInstant'
}
,'従業員数(人)':
{ 'element_id':['NumberOfEmployees']
,'contextRef':'CurrentYearInstant'
}
, '売上高':
{'element_id':
# 売上高
['RevenuesFromExternalCustomers'
,'TransactionsWithOtherSegments'
,'NetSales'
,'OperatingRevenue1'
,'OperatingRevenue2'
,'GrossOperatingRevenue'
,'OrdinaryIncomeBNK'
,'OperatingIncomeINS'
# 営業収益
,'OperatingRevenue1SummaryOfBusinessResults'
,'OperatingRevenue2SummaryOfBusinessResults'
# 経常収益
,'OrdinaryIncomeSummaryOfBusinessResults'
]
,'contextRef':'CurrentYearDuration'
}
, '売上原価':
{'element_id':
# 売上原価
['CostOfSales'
# 営業費用
,'OperatingExpenses'
# 営業原価
,'OperatingCost'
]
,'contextRef':'CurrentYearDuration'
}
,'売上総利益':
{ 'element_id':['GrossProfit']
,'contextRef':'CurrentYearDuration'
}
,'営業利益':
{ 'element_id':['OperatingIncome']
,'contextRef':'CurrentYearDuration'
}
,'経常利益':
{ 'element_id':['OrdinaryIncome']
,'contextRef':'CurrentYearDuration'
}
,'当期純利益':
{ 'element_id':['ProfitLoss']
,'contextRef':'CurrentYearDuration'
}
,'親会社の所有者に帰属する利益':
{ 'element_id':['ProfitLossAttributableToOwnersOfParent']
,'contextRef':'CurrentYearDuration'
}
,'自己資本比率':
{ 'element_id':['EquityToAssetRatioSummaryOfBusinessResults']
,'contextRef':'CurrentYearInstant'
}
,'ROE(自己資本利益率)':
{ 'element_id':['RateOfReturnOnEquitySummaryOfBusinessResults']
,'contextRef':'CurrentYearDuration'
}
,'EPS(一株当たり利益)':
{ 'element_id':['BasicEarningsLossPerShareSummaryOfBusinessResults']
,'contextRef':'CurrentYearDuration'
}
,'BPS(一株当たり純資産)':
{ 'element_id':['NetAssetsPerShareSummaryOfBusinessResults']
,'contextRef':'CurrentYearInstant'
}
,'流動資産':
{ 'element_id':['CurrentAssets']
,'contextRef':'CurrentYearInstant'
}
,'固定資産':
{ 'element_id':['NoncurrentAssets']
,'contextRef':'CurrentYearInstant'
}
,'資産計':
{'element_id':
['Assets'
,'TotalAssetsSummaryOfBusinessResults'
,'TotalAssetsIFRSSummaryOfBusinessResults'
]
,'contextRef':'CurrentYearInstant'
}
,'流動負債':
{ 'element_id':['CurrentLiabilities']
,'contextRef':'CurrentYearInstant'
}
,'固定負債':
{ 'element_id':['NoncurrentLiabilities']
,'contextRef':'CurrentYearInstant'
}
,'負債計':
{ 'element_id':['Liabilities']
,'contextRef':'CurrentYearInstant'
}
,'純資産':
{ 'element_id':['NetAssetsSummaryOfBusinessResults']
,'contextRef':'CurrentYearInstant'
}
,'営業CF':
{ 'element_id':['NetCashProvidedByUsedInOperatingActivities']
,'contextRef':'CurrentYearDuration'
}
,'投資CF':
{ 'element_id':['NetCashProvidedByUsedInInvestmentActivities']
,'contextRef':'CurrentYearDuration'
}
,'財務CF':
{ 'element_id':['NetCashProvidedByUsedInFinancingActivities']
,'contextRef':'CurrentYearDuration'
}
}
上記を使って、XBRLファイルを読み込み、リスト型にデータを格納します。
def load_edinet():
edinet_list = []
# xbrl 読み込み
xbrl_files = glob.glob(const.FOLDER_XBRL + '*.xbrl' )
# EdinetcodeDlInfo.csv 読み込み
edinetcodedata = pd.read_csv(const.FILE_EDINETCODE, skiprows=1,encoding='cp932')
for index, xbrl_file in enumerate(xbrl_files):
ctrl = Cntlr.Cntlr()
model_manager = ModelManager.initialize(ctrl)
model_xbrl = model_manager.load(xbrl_file)
print(xbrl_file, ":", index + 1, "/", len(xbrl_files))
# XBRLをDataFrameにセット
factData = pd.DataFrame(
data=[(
fact.concept.qname.localName,
fact.value,
fact.isNumeric,
fact.contextID,
fact.decimals
) for fact in model_xbrl.facts ],
columns=[
'element_id',
'value',
'isNumeric',
'contextID',
'decimals'
])
# 取得したい要素
datalist = []
datalist_ren = []
flg_ren = False
for key, value in dict_cols.items():
contextRef = value['contextRef']
element_ids = value['element_id']
if len(element_ids) > 0:
for element_id in element_ids :
# data1 = factData[factData['element_id'].str.contains(element_id)]
data1 = []
data2 = []
data3 = []
data1 = factData[factData['element_id'] == element_id]
if len(data1) == 1 : break
data2 = data1[data1['contextID'] == (contextRef + '_NonConsolidatedMember')]
data3 = data1[data1['contextID'] == contextRef ]
if len(data2) >= 1 or len(data3) >= 1 : break
data,data_ren,unitRef = '','',''
if len(data1) == 1 :
data = data1['value'].values[0]
data_ren = data
print(key + ' : ' + data)
if len(data2) >= 1 and len(data3) == 0:
data = data2['value'].values[0]
data_ren = data
print(key + ' : ' + data)
if len(data3) >= 1 :
data = ''
data_ren = data3['value'].values[0]
print(key + '(連結) : ' + data_ren)
if len(data1) == 0:
print(key + ' : ' + 'NoData ')
data = ''
datalist.append(data)
if flg_ren :
datalist_ren.append(data_ren)
if key == 'EDINETコード':
company = edinetcodedata[edinetcodedata['EDINETコード'] == data]
if len(company) == 1 :
print('提出者業種 : ' + company['提出者業種'].values[0])
data = company['提出者業種'].values[0]
flg_ren = False
if company['連結の有無'].values[0] == '有':
print('連結の有無 : ' + company['連結の有無'].values[0] )
flg_ren = True
else:
print('提出者業種 : ' + 'NoData ')
data = ''
datalist.append(data)
datalist.append('連結' if flg_ren else '単独')
if flg_ren :
# 連結用にデータをコピー
datalist_ren = datalist[:]
if flg_ren :
edinet_list.append(datalist_ren)
else:
edinet_list.append(datalist)
return edinet_list
最後に以下でCSV出力します。
df = pd.DataFrame(edinet_list,columns=dict_cols.keys())
df.to_csv(const.FILE_EDINET_CSV, encoding='cp932')
print('Finish. Write to csv.')
最終的なソースはGitHubにあります。









コメント
コメント一覧 (5件)
はじめまして。
当方Python初学者です。
GitHubのソースコードを拝見させていただいきまして、質問があるのですが、よろしいでしょうか?
最初の方で読み込んでいる、const.py(モジュール?)はどのような構成になっていて、どこにあるのかご教示いただけませんでしょうか?
パンピーさま
コメントありがとうございます。const.pyをあげてなくてすみません。Githubにコミットしましたのでご確認ください。ありがとうございました。
さっそくの対応ありがとうございました。
確認させていただきます。
はじめまして、こちらのブログをはじめて拝見しました。以下のCSVはどこから入手可能でしょうか? EDINETの公式サイトでしょうか? よろしくお願いいたします。
EdinetcodeDlInfo.csv
CompanyInfo.csv
Edinet.csv
頑張れニッポンさま
コメント&ご指摘ありがとうございます。
EdinetcodeDlInfo.csvはEDINETの公式サイトにあるEDINETコードリストです。ダウンロードページにある「EDINETタクソノミ及びコードリスト」で一番下に出てきます。
CompanyInfo.csvはソース上使っていませんでした。すみません、無視してください。
Edinet.csvは出力用ファイルです。