
こんにちは。
2021/3/18に「Google Chrome」にライブキャプション(自動字幕起こし)機能を追加されました。
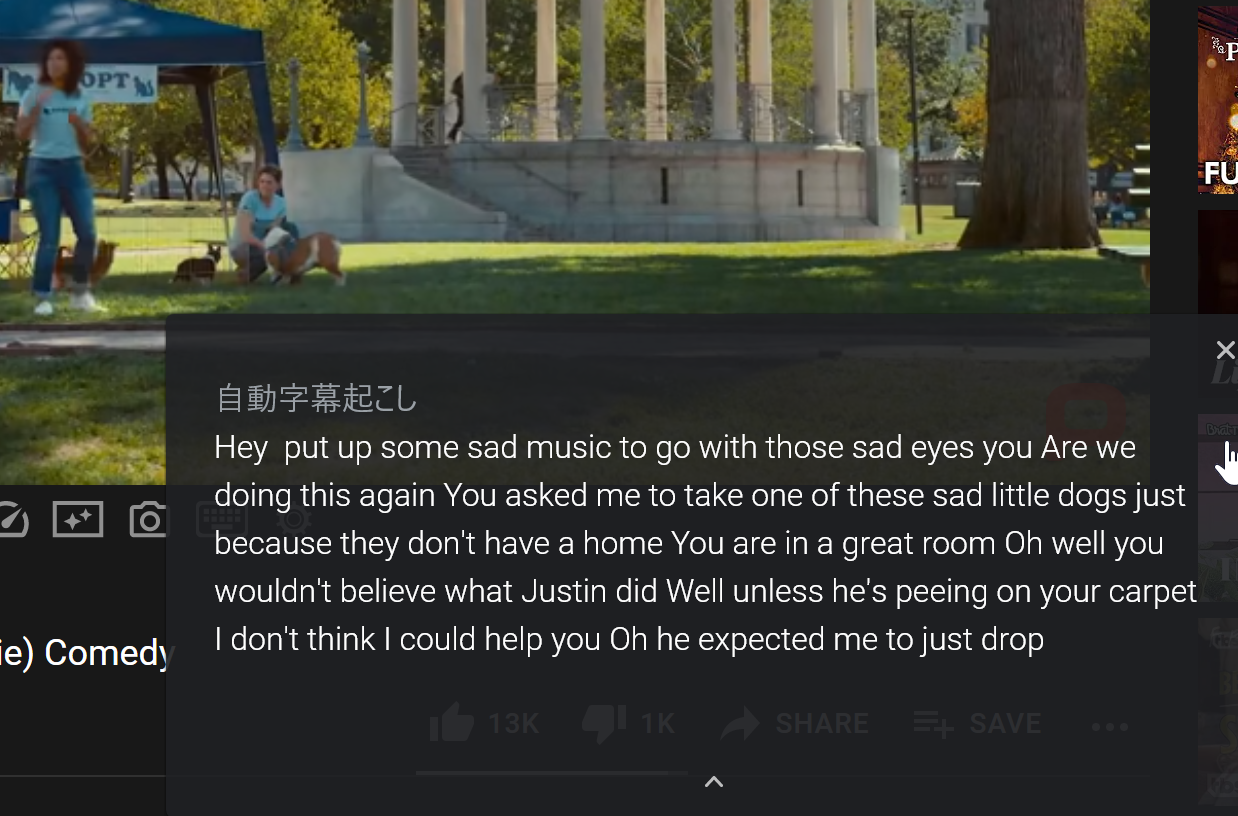
英語のみの対応ですが、Chromeで再生された動画が全て自動で字幕になるすごい機能です。ただなぜか、字幕が自動翻訳までは対応していないのと、なぜかコピペ出来ないので、英語の文字がただ流れているだけとなっております。あまり英語が得意でない私の場合、役に立ちません。近いうちに自動翻訳とか出来るようになると思うんです。どうかお願いします。
そんな事がきっかけで音声データの文字起こしについて、CMUSphinxという音声認識エンジンを使って試してみました。ちなみに音声認識エンジンでは「Google Cloud Speech API」が有名ですが、 無料枠は60分/月までとなっています。60分はすぐに越してしまいそうだったので、無料で使用できるCMUSphinxに行きつきました。
CMUSphinxとはカーネギーメロン大学のスフィンクスグループが開発したオープンソースの音声認識エンジンです。CMUSphinxを簡単に使用できる「SpeechRecognition」というライブラリを使用します。ちなみにSpeechRecognitionでは「Google Cloud Speech API」も利用することができます。
CMUSphinxをpythonで使用する場合は、CMUSphinxのツールキットである「pocketsphinx」が便利です。以下でインストールします。
pip install pocketsphinx
ただし、今回GoogleColabで使用しているので、以下を先にインストールします。
apt-get install -y python python-dev python-pip build-essential swig git libpulse-dev
そしてSpeechRecognitionもインストールします。
pip install SpeechRecognition
あとは、以下サンプルの真似をしてみます。3分弱のサンプルwavファイルの文字起こしを試しました。
https://github.com/Uberi/speech_recognition/tree/master/examples
from glob import glob
import speech_recognition as sr
path = '/content/'
for filepath in glob(path + '*.wav'):
print(filepath)
r = sr.Recognizer()
with sr.AudioFile(filepath) as source:
audio = r.record(source)
try:
print("Sphinx thinks you said " + r.recognize_sphinx(audio))
except sr.UnknownValueError:
print("Sphinx could not understand audio")
except sr.RequestError as e:
print("Sphinx error; {0}".format(e))
精度はGoogleほどよくないという噂でしたが、十分な精度な気がしました。ただ10分ほどのwavファイルは完了しなかったので、1度に文字起こしできる時間は限られているようです。


コメント