
こんにちは。
機械学習をする上で分散処理の事を勉強しているので、少しずつまとめていこうと思います。
Hadoopアーキテクチャ概要
Hadoopとは、大規模なデータをコモディティサーバー(価格を抑えた汎用の中級クラスのPC/ブレード・サーバー)のクラスターに分散処理することを可能にするオープンソースのフレームワークです。Hadoopは、1台のサーバーから数千台のマシンにまで拡張できるように設計されており、耐障害性があり、高いスループットとデータ損失のリスクが低いという特徴があります。
Hadoopアーキテクチャは、3 つの主要なレイヤーで構成されています。
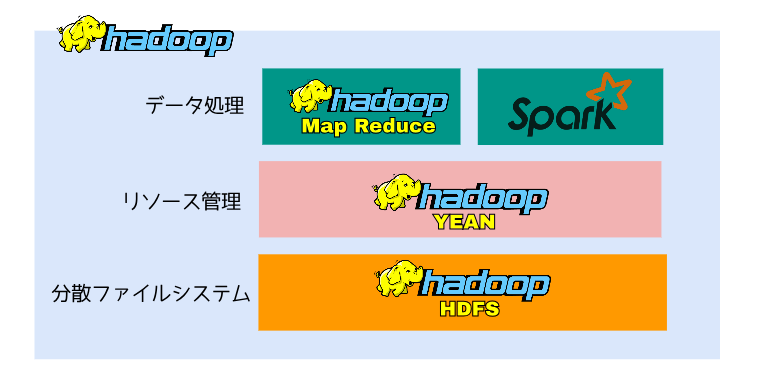
分散ファイルシステム(HDFS)
分散ファイルシステム(HDFS)はファイル管理を担当します。複数のマシンにファイルを分割して格納する事が出来ますが、ユーザーからは一つのファイルを扱うようにしか見えません。
リソース管理(YARN)
YARNは、対話型SQL、リアルタイムストリーミング、データサイエンス、バッチ処理などの複数のデータ処理エンジンが単一のプラットフォームに格納されたデータを扱うことを可能にします。
データ処理(MapReduce,Spark)
大量のデータを並行して処理するフレームワークです。沢山ありますが、MapReduceとSparkが有名です。MapReduceとSparkについて次に説明していきます。
MapReduce概要
MapReduceはHadoopのデータ処理層です。MapReduceは、MapタスクとReduceタスクで構成されています。Mapタスクの機能は、データの読み込み、解析、変換、フィルタリングを行います。入力データをKey,Valueに分解します。これをReduceタスクに渡します。Reduceタスクは、Mapタスクから受け取ったKey,Valueを集約して要約します。

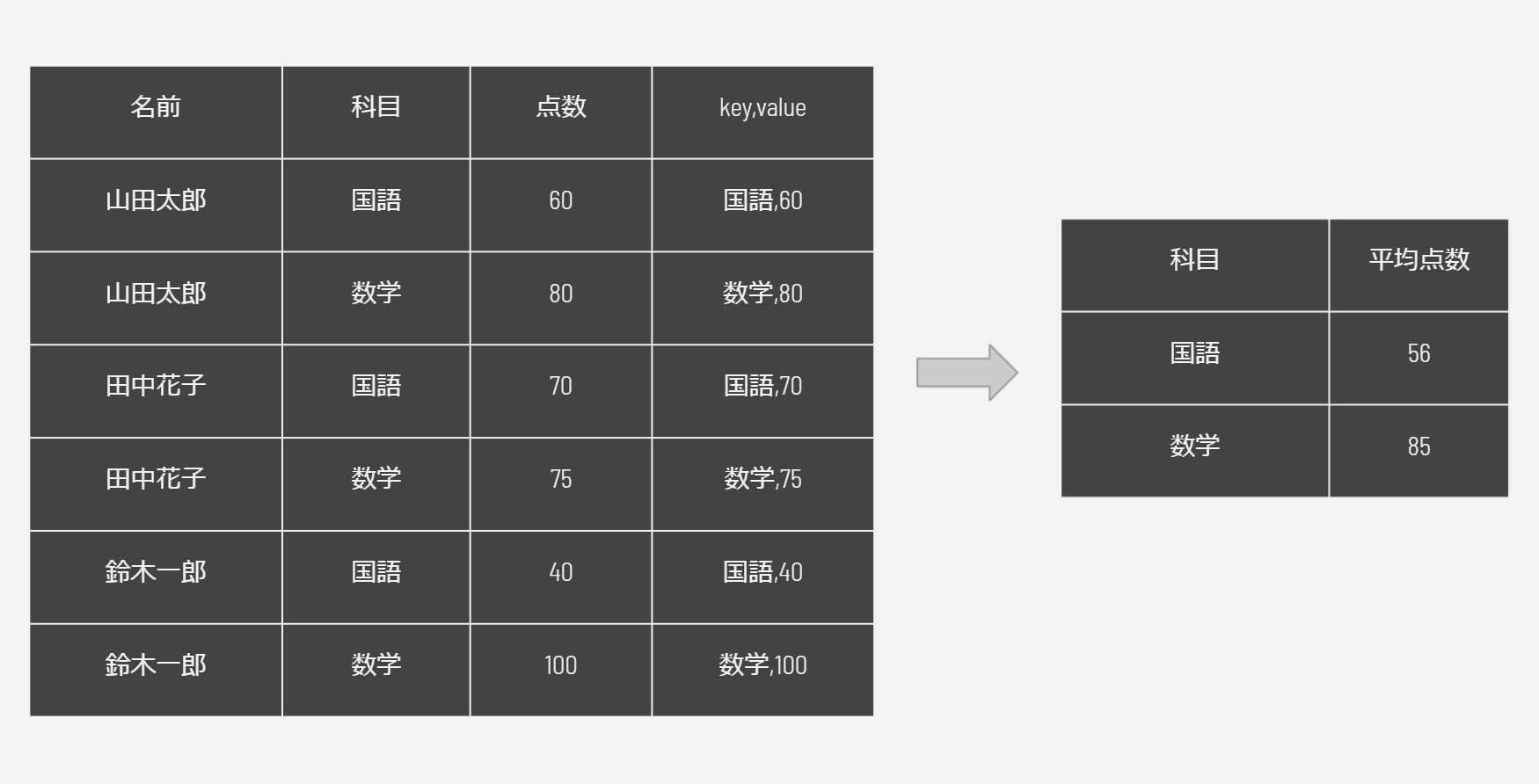
具体的な例を入れて説明します。
Mapタスクがそれぞれの国語と数学の点数をkey,valueとしてReduceタスクに渡します。Reduceタスクはそれぞれの平均を計算します。
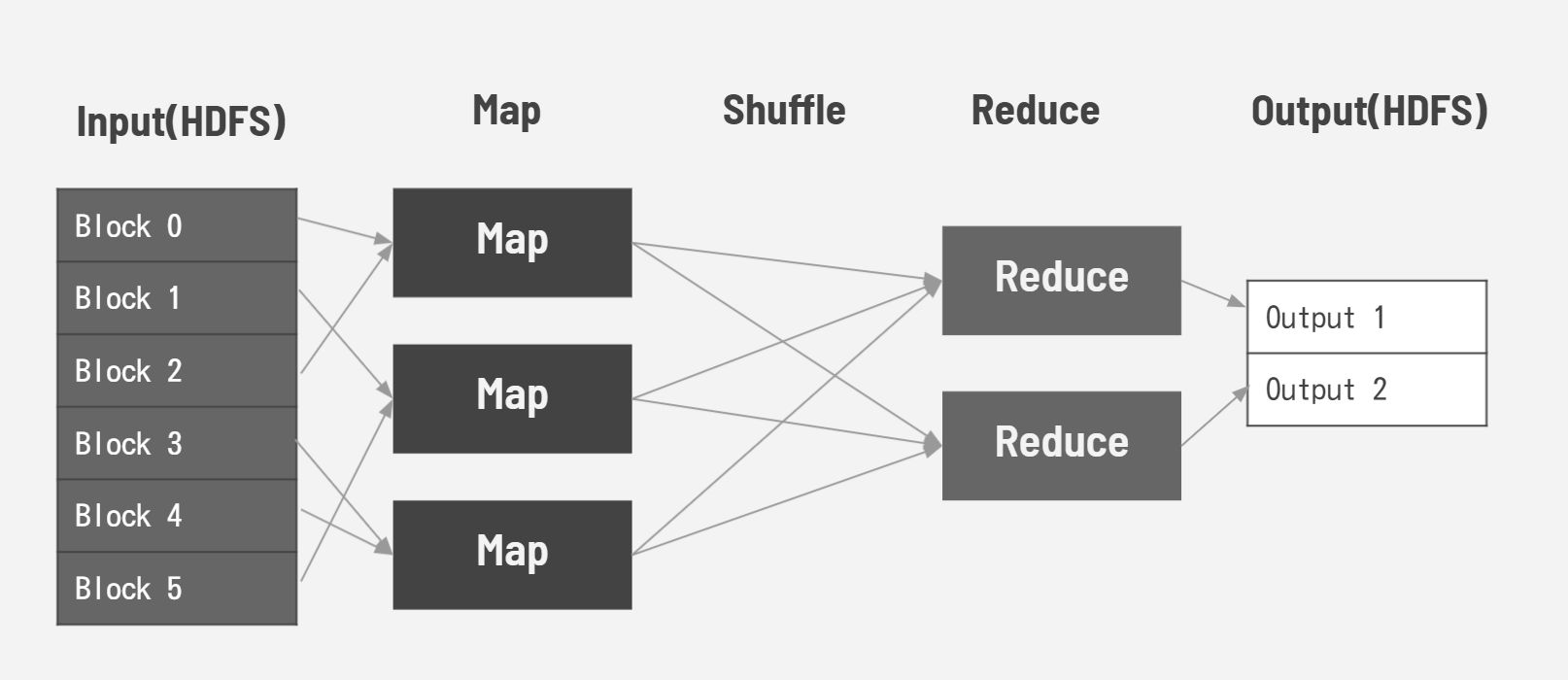
それを分散して以下のように実行するイメージです。MapタスクとReduceタスクの間にShuffleタスクがあります。Shuffleタスクではkeyをまとめますが、ユーザが意識するものではありません。
Spark概要
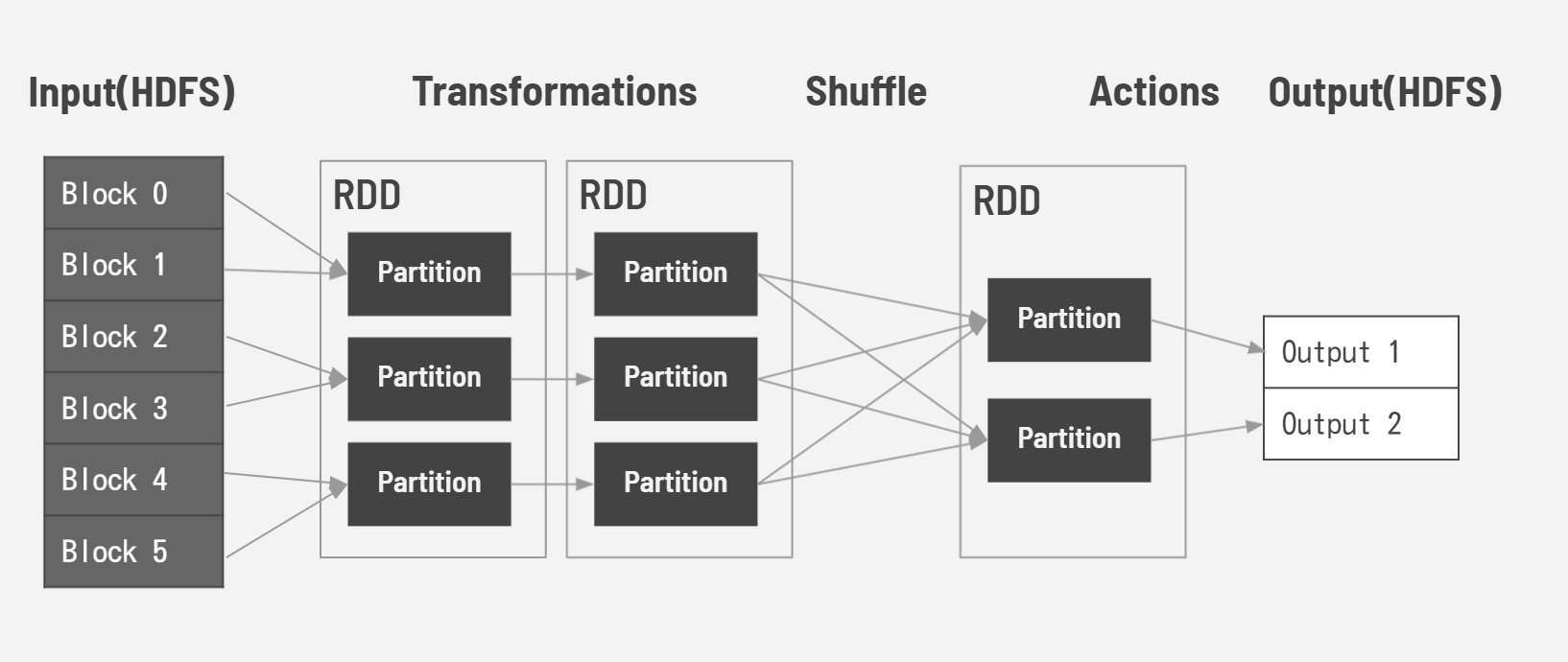
Sparkは、MapReduceを高速化するために開発されました。MapReduceはHDFSの読み書きに90%以上の時間を費やしています。Sparkはリアルタイムのデータ処理をメモリ内計算することで、処理時間を大幅に減らす事が出来ます。RDD(Resilient Distributed Datasets)という分散共有メモリの仕組みです。SparkRDDには「Transformations」と「Actions」の2つの操作があります。1つのRDDは複数のパーティションに分割され、パーティションごとに並列に変換処理(Transformations)を行います。また処理の途中でパーティション間のデータ交換(シャッフル)を行います。Actionsは値を返す操作です。


コメント